




Precise feeding in the recirculating aquaculture mode is a critical problem. Accurate prediction of shrimp biomass could determine the appropriate feeding amount and ensure stable water quality. This review presents the development of an intelligent feeding technique in a recirculating aquaculture system for rearing Litopenaeus vannamei.
Researchers have used machine learning to carry out a series of studies on early warning and aquaculture strategy formulation. In recent years, the application of machine learning in aquaculture has included prediction of water quality indicators, early warning of diseases and red tide outbreaks, and fish stock prediction.
Using sensor technology to monitor and regulate the culturing process will be the trend in the intelligent fishery. Bourke et al. (1993) developed a decision-making system that could feed back water quality indicators in real time.
“Novel detection methods and sensors are also constantly being developed. Wang et al. (2018) developed a novel optoelectronic sensor device for NO2 -N in a recirculating aquaculture system (RAS). “
The combination of sensors with the Internet of Things and artificial intelligence technologies has been widely used in aquaculture, making water quality prediction and early warning technologies more accurate and smarter.
Compared with the traditional extensive breeding mode, RAS is more conducive to sensor applications. RASs can provide high production as an effective aquaculture approach due to their controlled, bio-secure environment based on an artificial ecosystem. It also, can produce high-quality seafood with low water exchange regardless of the external environment.
White shrimp (Litopenaeus vannamei) cultured in a RAS can grow at high density, avoiding harmful viruses. Moreover, a land based system with limited water exchange has great potential to reduce the environmental load of a water treatment process (Martins et al., 2010).
“While shellfish are in a RAS, the reared animals’ biomass is hard to calculate accurately, especially when the culture tank is large. To guarantee sufficient and appropriate feed, counting numbers and total weight by sampling a unit area is a common way of measuring biomass (Chen et al., 2019). “
Accurate estimation of shrimp biomass in a RAS provides significant guidance for feeding. The biomass can determine the appropriate feeding amount, ensuring clean water quality and providing adequate nutrition for shrimp.
Researchers have carried out many related studies on applying empirical models to predict shrimp biomass. However, the models cannot be directly applied to a RAS due to the different modes, methods and environments of the rearing process.
Here we present the summary of a study where several models were used to forecast shrimp biomass to determine the appropriate feeding strategy in a RAS.
Materials and methods
Experimental materials and system
Litopenaeus vannamei rearing was carried out at two corporations in China. As shown in Figure 1a, b, the experiments were performed at Yujia’ao Ecological Technology (from June to November 2018) and at Guangdong Haimao Investment (from June to December 2019).
Figure 1c shows the shrimp reared in a single tank. Two sets of RASs were arranged for 680 thousand shrimp, and the larvae were reared up to 30mm in length. During the water treatment process, ultraviolet generation and ozone were applied to prevent viruses and pathogens.

A dirt collecting device was installed to guarantee water quality in each tank. Shrimp were fed on commercial feed six times a day. In the early stage of shrimp culture, the feeding amount was 5%–8% of total shrimp biomass.
The feeding amount was diminished with the passage of rearing time and finally reduced to ~3% of total cultured biomass. Figure 1d shows a schematic of the RAS.
“The combination of the centrifugal pump and the oxygenation cone contributed to the recirculation loop. The centrifugal pump drew water to a high elevation inside the biofilter and then poured water into a pipeline and recirculated it by gravity.”
An oxygenation cone was combined with a low-flow pump to provide sufficient dissolved oxygen. A disinfection subsystem, including an ultraviolet and ozone generator, was able to prevent infection from viruses and other pathogenic microorganisms.
Machine learning methods
Artificial neural networks (ANN) are derived from the biological neural networks in the human brain. Unlike networks with only a few layers of one-directional logic, they use algorithms to manipulate determination and organization of functions. Interconnected artificial neural networks are usually composed of neurons that can deal with the inputs and follow various situations.
“In the present study, several ANN methods, including the general regression neural network (GRNN), backpropagation neural network (BPNN), extreme learning machine (ELM) and recurrent neural network (RNN), were used to develop biomass prediction models.”
The sigmoid function was applied in the model development process. GRNN, BPNN and ELM are feedforward neural networks with no cycles or loops.
Support vector machine
As an efficient machine learning technique principally based on statistical theory, the support vector machine (SVM) focuses on limited information about samples and moves between the complexity and the learning ability of models, which possess an extraordinary knowledge of optimization worldwide to improve generalization.
As for the linear separable binary classification, finding the optimal hyperplane that divides all samples with maximum margin is the principal function of an SVM. The plane could improve the model’s predictive capacities and minimize the errors that are likely to emerge randomly when the statistics are being classified.
Model optimization
A genetic algorithm (GA) was used to optimize the machine learning methods, including ELM, BPNN and SVM, in the present study. GA is an evolutionary algorithm used to optimize a data-driven computational model with a combination of selection, crossover and mutation to evolve the initial random population.
Figure 2 shows a schematic of the machine learning GA (ML-GA).

The first GA optimization process involves choosing a fitness function that measures the performance of a set of input parameters. A solution with higher fitness derived from the fitness function will be better than any lower-fitness solution.
“A population is generated, and the appropriate time is taken to process each generation as system costs for calculating fitness and generating each population. The population goes through parent selection, where the best solutions will be selected to create the next generation of solutions.”
The parents will then go through the crossover process, and the children generated go through a mutation phase. The survivor selection stage will decide which individuals can move on to the next generation. The whole process will be repeated until the algorithm converge based on some convergence criterion.
Design of intelligent feeding system
The water environment needs to be regulated based on experience because the shrimp RAS contains a controllable artificial ecosystem. Different levels of experience will lead to varying regulation results and unstable production.
Figure 3 shows the design of the intelligent feeding system. There is a complex interaction between biomass, feeding amount and water quality. The shrimp biomass can directly determine the feeding amount, and water quality is mainly affected by biomass and feeding amount in a RAS.

Therefore, in this study, an intelligent feeding system was designed based on the shrimp biomass prediction model.
Machine learning approaches were used to calculate the feeding amount. The embedded system can then read the water quality index measured by the sensor, call the machine learning model and control the feeding machine to regulate the feeding strategy in the RAS.
Results
MLR model
Water temperature, salinity, pH, DO, TAN, NO2-N and total feed amount were successively introduced into the MLR model. Each variable needed to go through the F-test before being introduced into the model, and the t-test was performed on the introduced variables.
“When the introduced variables were no longer significant to the model, subsequent variables were deleted to ensure that the equation contained only significant explanatory variables.”
Variables were introduced step by step through arrangement and combination to ensure that the obtained equation had the best explanatory power. Finally, an expression with four explanatory variables was constructed as follows:

where W represents shrimp biomass (kg/m3 ), x1 represents water temperature (°C), x2 represents salinity (‰), x3 represents pH, and x4 represents total feed amount (kg/d).
The MLR model passed the t-(p<0.05) test and F-(F = 148.512) test with a regression coefficient (R2 ) of 0.882. Training machine learning models The machine learning methods, including GRNN, BPNN, LSTM, ELM and SVM, were used to develop models.
“The data set was divided into a 75% training set and a 25% testing set. The training set data were used to develop predicting models, and the test set data were substituted into the models for evaluation and verification.”
Figure 4 illustrates the data distribution curves of the GRNN, SVM, ELM and LSTM training sets. The RMSE showed that the GRNN and SVM model calculation results were accurate and that the prediction ability of the training set was stable.
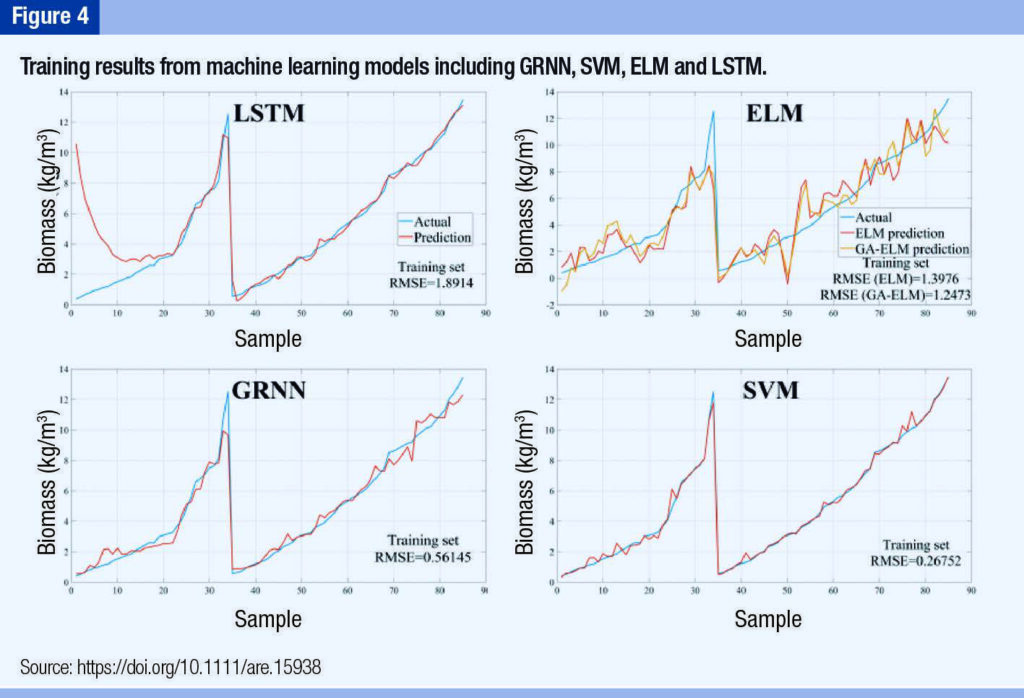
The RMSEs of the LSTM and ELM training sets were much larger, and the predicted results were quite different from the actual values. Predictive performance The test set contained 22 group data points.
The prediction performance was evaluated by preliminary observing the degree of overlap between the predicted result and the actual value.
Figure 5 shows the actual versus predicted values for the test set. X and Y have the same range, and the diagonal represents the regression standard. The closer a scatter point is to the diagonal, the closer that prediction is to the actual value.

Figures 5 illustrates that the test set predictions from the SVM and GRNN models were more accurate than those from the other machine learning models.
Model comparison
Residual plots can be used to estimate whether the prediction errors (residuals) are consistent with the stochastic errors.
Figure 6 shows residual plots of the shrimp biomass prediction models. The residual represents the difference between the actual value and the predicted value of shrimp biomass. By analyzing the residual plot, the degree of dispersion of the prediction results can be observed.

SVM and GRNN had the highest accuracy (90.91%), whereas LSTM had the lowest accuracy (22.73%).
Conclusions
MLR, ANNs and SVM methods were used to construct biomass prediction models for L. vannamei in a RAS. The MLR method extracted four main explanatory variables: water temperature, dissolved oxygen, pH, and total feeding amount and constructed a linear relationship between shrimp biomass and its main explanatory variables.
“The model passed the t-test and F-test (R2 = 0.882). Biomass prediction models based on machine learning approaches were developed using the data set, and a genetic algorithm was used to optimize the models further.”
Four indices (MAE, RMSE, MAPE and accuracy) were used to evaluate the deviation of the prediction models. SVM was selected as the optimal shrimp biomass prediction method after comparing the predicted results, residual analysis and evaluation indices between different models (RMSE = 0.6500, MAE = 0.4368, MAPE = 3.70%, accuracy = 90.91%).
Finally, a fast-responding shrimp biomass prediction model for a RAS was developed using the SVM method with GA optimization. The intelligent feeding system can apply the SVM model to regulate the precise feeding amount in a L. vannamei RAS.
This is a summarized version developed by the editorial team of Aquaculture Magazine based on the review article titled “INTELLIGENT FEEDING TECHNIQUE BASED ON PREDICTING SHRIMP GROWTH IN RECIRCULATING AQUACULTURE SYSTEM” developed by FUDI CHEN and MING SUN – Institute of Oceanology, Chinese Academy of Sciences, Qingdao, China; Qingdao National Laboratory for Marine Science and Technology, Qingdao, China; Dalian Key Laboratory of Conservation of Fishery Resources, Dalian, China, YISHUAI DU, JIANPING XU, LI ZHOU, TIANLONG QIU and JIANMING SUN – Center for Ocean Mega-Science, Institute of Oceanology, Chinese Academy of Sciences; Qingdao National Laboratory for Marine Science and Technology, Qingdao, China.
The original article was published in AQUACULTURE RESEARCH in MAY 2022.
The full version, including tables and figures, can be accessed online through this link: https://doi.org/10.1111/are.15938



